In machine learning, there is a prevalent problem known as overfitting. What is it, and how should we prevent it from occurring in your model? Let’s find out in this article.
How Does Overfitting Occur?
To understand how this problem happens, let’s explore how a machine learning algorithm learns things first. First, a dataset is supplied to the model, which can take many forms, including a regression or decision tree model. The data can also be of many types, including numerical data, discrete categories, strings, and images. After that, the model is trained to perform best on the dataset it receives.
This is where the quality of your model comes in. At the start, the models are of similar quality, but when you train the models differently, the performance changes. For instance, if you only train the model with a single dataset, it will not be able to predict anything accurately. It only fits itself into the small piece of data instead of asking for more information. This causes the concept that the more real-world data the model is being trained for, the more accurate the model is.
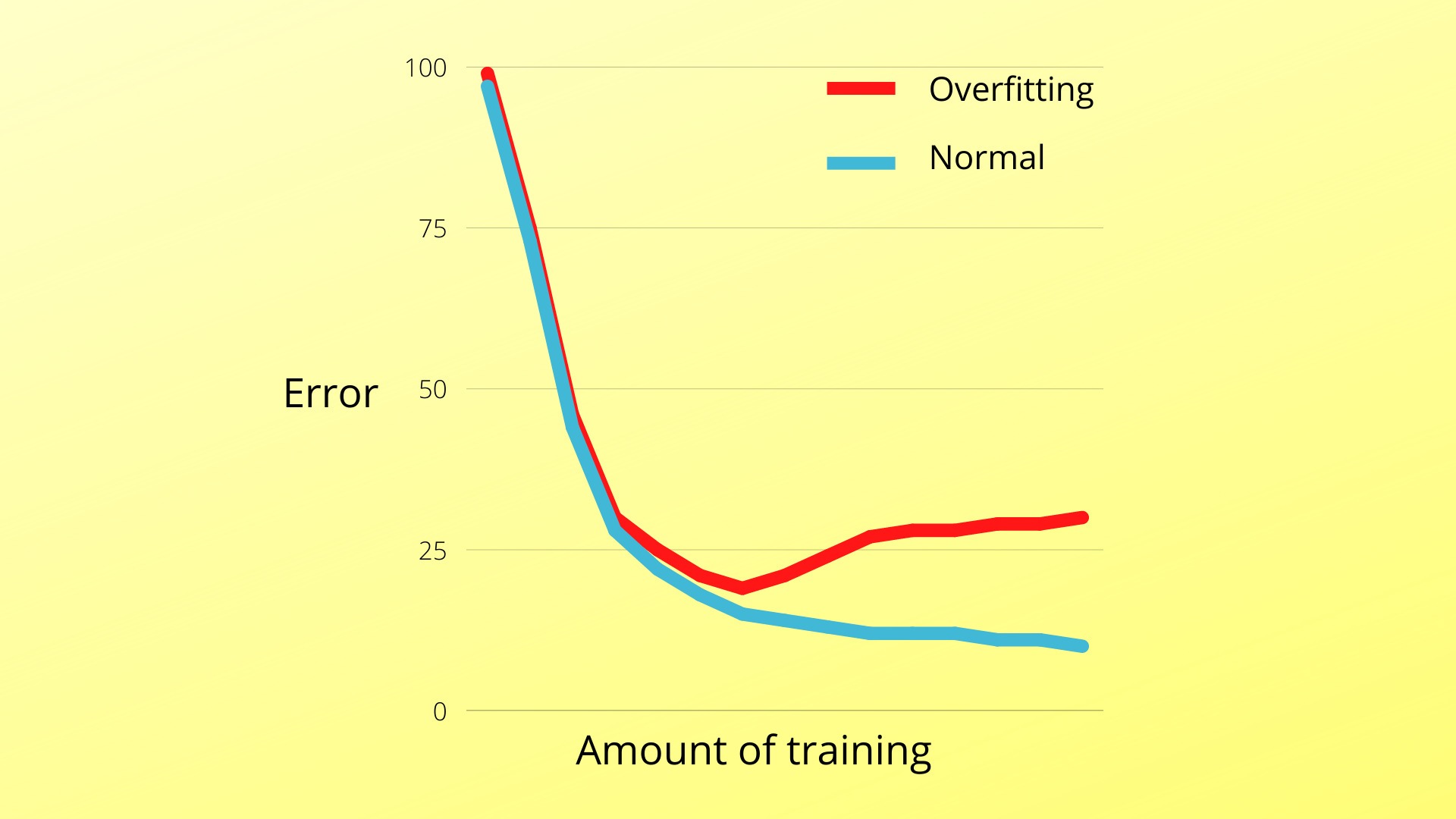
However, the quality of the data is just as important as the quantity. That’s where overfitting comes in. When your data is not collected correctly, the model might explicitly fit in the dataset but performs less reliably in other real-world situations or the test data. In the next section, we’ll explore the telltale signs of overfitting and how it should be fixed.
The Signs of Overfitting
How do you know that this problem has occurred in your model? Give it an assessment first. Don’t use all your data for training the model. Instead, put some information aside for testing your model. This is one of the best ways to detect overfitting and other problems with your model, especially if it happens unexpectedly.
If your model performs poorly on the test data even though you have trained it on lots of information, or if the variance is high on the performance between the testing and training datasets, the culprit is almost certainly overfitting. How do you fix this issue and improve your model’s performance in the real world? Let’s find out about it.
Fixing and Preventing Overfitting
Here is a rule of thumb: You cannot blame the model if you find out that it overfits into the dataset because the model has been well-written and well-debugged. You can only suspect that the quality of your data and how you train the model are responsible.
Firstly, you should ensure that the data you give the model is as diverse as possible, preferably achieving the same amount of diversity as in real-world situations. In that case, the model will not become biased in analyzing one type of data. Instead, it generalizes to take all kinds of data it will encounter in real life into account, improving its accuracy.
Secondly, it is advisable to examine the features needed for prediction. Putting too many features might bias the system, so you are more likely to overfit it. Try removing some features you deem unnecessary or negligible to your final decision. If the model performs better this time, you were likely overfitting the model last time, and you happened to fix the problem, at least partially.
Thirdly, ensemble modeling is also a good idea if you want to prevent overfitting in your model. That means training multiple models using different random parameters and combining their results by taking the mean or median of each of their outputs. Alternatively, the model can choose what most models think a specific option is a correct answer. This reduces overfitting as the models each have their advantages and disadvantages, and this method groups all the models so that cumulative overfitting or underfitting will decrease.
Conclusion
In this article, we’ve discussed the definition of overfitting, how we should identify whether it is occurring, and how to fix and prevent it by optimizing your data and your models. If we have missed any critical points we should have discussed, please leave them in the comments below to enhance this article.