Deep learning is one of the most common types of machine learning, and it is currently pushing the limits of what we can achieve with artificial intelligence. However, you may want to ask, ‘What is this piece of technology about?’. This article has the answer for you. Let’s find out.
Neural Networks
To understand deep learning, we first need to know about neural networks. Neural networks are a group of interconnected neurons in machine learning. Each neuron receives upstream data points, manipulates them based on what it’s instructed to do, and sends its output to other downstream neurons. Therefore, a neural network does computation based on its adjustable neurons, which is why neural networks are trainable.
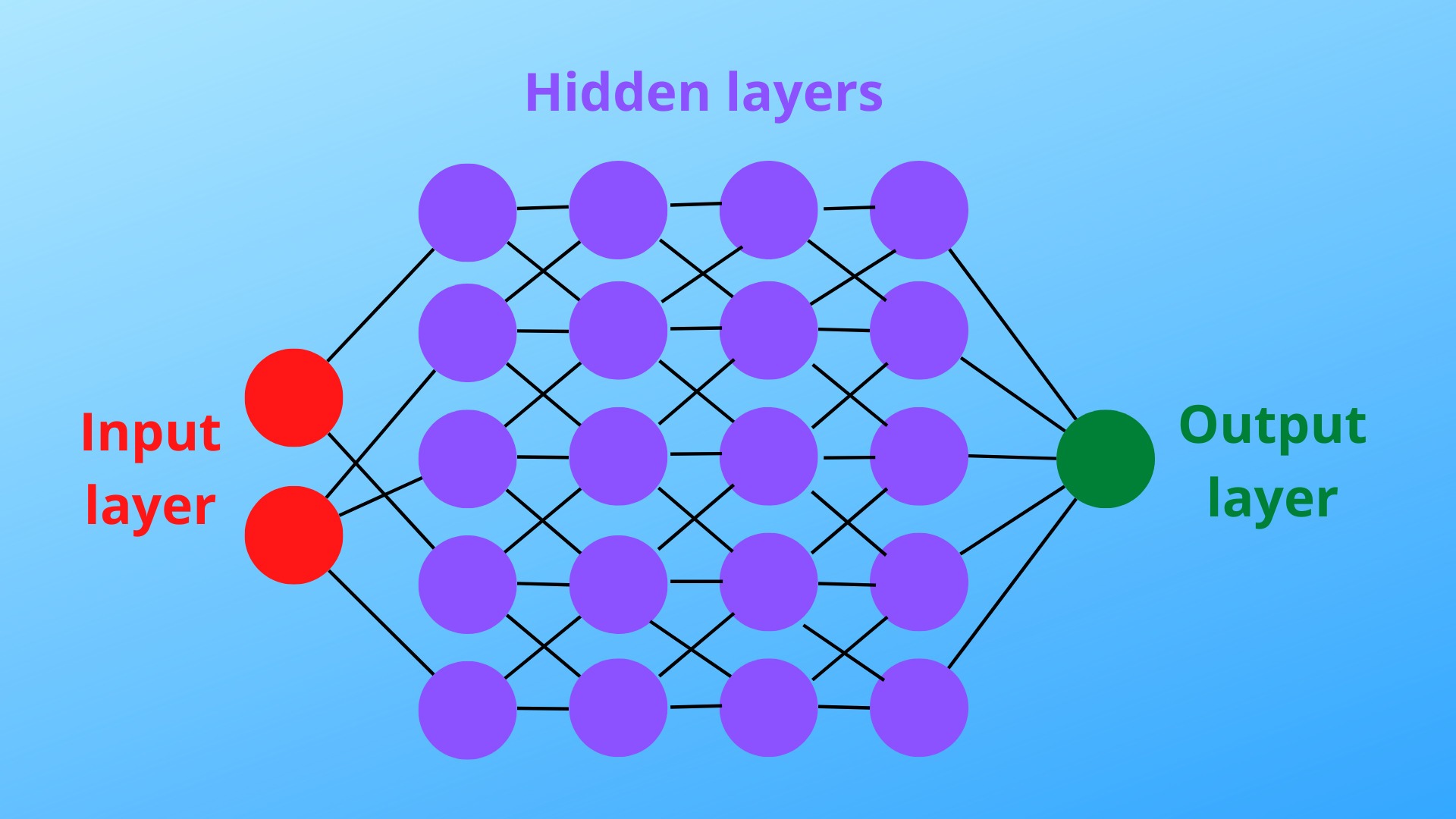
In neural networks, neurons are not connected in a random or unorganized way. Instead, they are arranged into layers, which can be classified into three types: Input layers, hidden layers, and output layers. Input layers accept input and send the data onto the hidden layers, while output layers turn the result of upstream neurons into outputs that are then stored as variables. Usually, a neural network has only one input layer and one output layer as they are all that’s needed for their purpose. However, they can have multiple hidden layers, which is where the main computation resides.

What is Deep Learning?
After talking about neural networks, it’s time to define deep learning in this article. A deep neural network is a neural network that contains more than one hidden layer, and deep learning is a type of machine learning using a deep neural network as a model.
As with other forms of machine learning, models are created and fitted with training data to train them. When the model is being trained, it seeks patterns from the model and tries to learn from it. However, a deep learning model tends to learn things more autonomously, as they essentially eliminate or reduce the time-consuming process of feature extraction and feature engineering. Instead, they can figure out which features are more important for the result, thus learning more from them.
A deep learning model can often fit more optimally than a classical machine learning model since it is more flexible. With multiple different layers of neurons, it can adjust its computation better as it fits the model, making it more accurate if it is trained correctly and supplied with sufficient data.
Where is Deep Learning Used?
Because deep learning is so powerful, it is used everywhere where machine learning is used. This includes natural language processing (NLP), where human language is being parsed and processed, and computer vision, where images and videos are analyzed for purposes such as object recognition and tracking. Deep learning is useful for generating predictions and general data analysis as well.
A Simple Implementation of Deep Learning
After discussing all of this, it may seem that cutting-edge deep learning libraries are unreachable and far away. However, this couldn’t be farther from the truth. In fact, with an adequate dataset and a few Python libraries, you can train your model with a few lines of code. In this section, we’ll focus on implementing a Tensorflow model, but some other models are also publicly available.
First, install Tensorflow using:
pip install tensorflowAfter that, you can import the modules:
import tensorflow
from tensorflow import kerasAfter that, prepare your data, extract the features, and perform a train-test split. Then, you can set up the model:
#Input layer
input = keras.layes.Input(x_train.shape[1])
#Hidden layers
x = keras.layers.Dense(64, activation="activation") (input)
x = keras.layers.Dense(64, activation="activation") (x)
x = keras.layers.Dense(64, activation="activation") (x)
#Output layer
output = keras.layers.Dense(y_train.shape[1], activation="activation") (x)
#Model
model = keras.Model(input, output)If you try to run the code directly, it won’t work because the activation function has not been specified. Choose an activation function based on the problem you want your model to solve and specify it in the activation parameter in the hidden layers. After that, apply optimizers and assessment metrics:
model.compile(optimizer="optimizer", loss='loss', metrics='metric')Again, you have to choose the optimizer, the loss function, and the metric yourself, depending on your model’s needs. Finally, we can train the model:
fitted_model = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=epochs, batch_size=batch_size)Again, you need to adjust the number of epochs and the batch size as the model is being trained. The optimal way to train a model varies according to the dataset and the model itself.
After your model is trained, you assess its performance and tweak its parameters until you think you are satisfied with its performance. Then, you can use the model for whatever you would like your model to do, whether it’s regression or classification.
Conclusion
In this article, we’ve explored what deep learning is, where it is used, why it’s so powerful, and a simple implementation of such a technique. If you want to learn more about this, please visit the webpages in the references below.
References
- (2020, May 1). What is Deep Learning? Retrieved July 31, 2022, from https://www.ibm.com/cloud/learn/deep-learning
- Puget, J. (2017, April 24). Feature Engineering For Deep Learning. Retrieved July 31, 2022, from https://medium.com/inside-machine-learning/feature-engineering-for-deep-learning-2b1fc7605ace
- Wolfewicz, A. (2022, July 26). Deep Learning vs. Machine Learning – What’s The Difference? Retrieved July 31, 2022, from https://levity.ai/blog/difference-machine-learning-deep-learning