Classification is one of the most common tasks in data science and machine learning. Today, in this article, we’ll learn how classification systems work and how you should assess your model’s performance to improve it.
Where is Classification Used For?
Before we examine how classification solutions work, we would like to introduce when this technique is used for. Basically, classification is the act of labeling a data point in an organized and desirable way, and there are many valuable applications of that.
For example, it can be used to predict values. For instance, you can predict the winner of a match using such a model or whether there will be inclement weather in the coming days. It can also be used for retrieving values with high accuracies, such as diagnosing a disease or determining the categories of each data point in the database to obtain statistics.
Note that classification is used for obtaining non-numerical, discrete categories. If your prediction results are made of numbers, you’d better use regression algorithms instead of classification algorithms.
How Do Classification Algorithms Work?
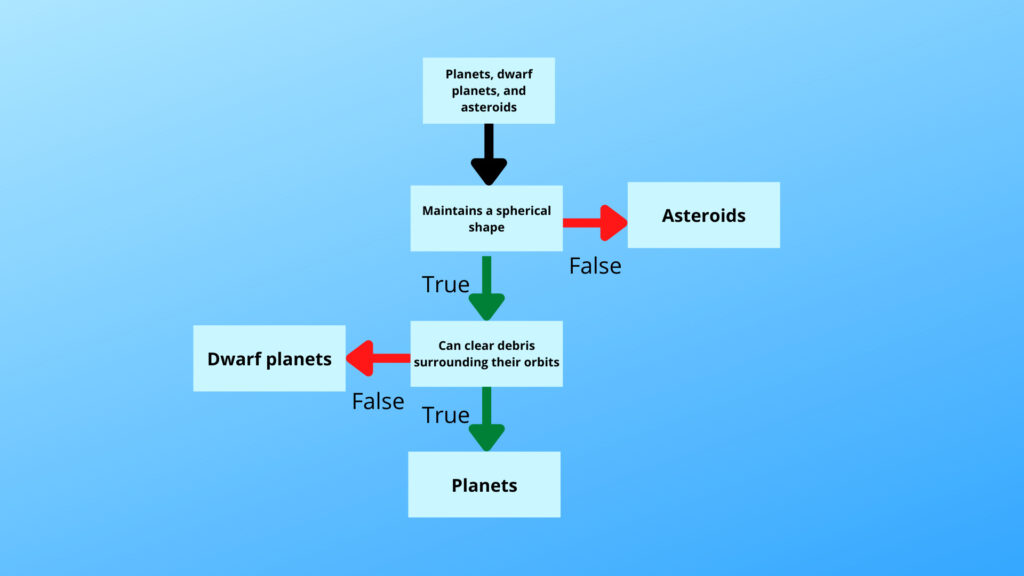
At this point, you may ask, “how do classification algorithms work”? Well, there are a few standard algorithms that you can use to classify things. The first one is a decision tree algorithm, which works by comparing features of one category with another. An example of a very simple decision tree is illustrated below. Note that real-life decision trees are much more complex than the one below for most scenarios.
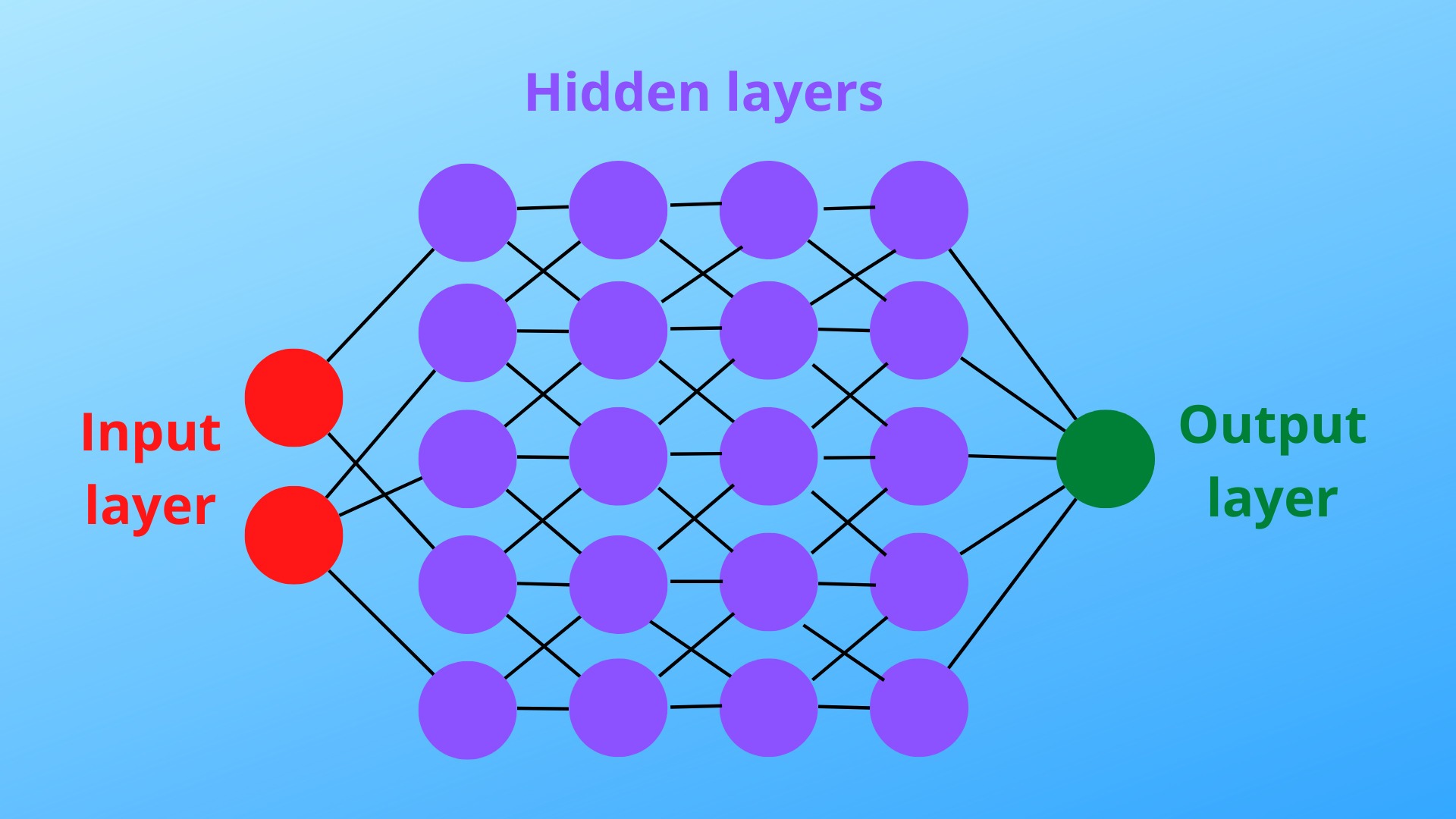
Besides decision trees, deep neural networks can also be used for classifications. They compose of neurons that manipulate input values so that output values are produced. Since they are more complex than most decision trees, they are often the preferred option for classification and other machine learning tasks.
How to Assess the Performance of a Classification System?
After your model has been trained, how to assess its performance? Well, a few metrics can do so, but first, you need to know the difference between binary and multi-class classification. Binary classification only contains two classes: True or false, positive or negative, and so on. Therefore, there is one correct answer, and the other answer is incorrect. Multi-class classification involves more than two classes, so there is one right answer and multiple wrong answers. We’ll first explore the metrics for binary classification in this section.
When evaluating whether a statement is true or false, there are four possibilities:
- A false statement is correctly identified (true negative).
- A false statement is incorrectly identified as a true one (false positive).
- A true statement is incorrectly identified as a false one (false negative).
- A true statement is correctly identified (true positive).
There are two metrics that can explore the relationships between these four categories, which is precision and recall. They are illustrated below:

Note that these two metrics are not interchangeable and should be used according to the scenario. For example, if you are using your model for anomaly detection, you will want to prefer minimizing the number of false negatives over reducing false positives. Therefore, the recall metric is the better option for that scenario.
For other classifications where all categories are treated fairly, like in image classification, accuracy is usually the best measure of your model’s performance. It measures the percentage of answers the model obtained correctly, and the higher the accuracy, the better the model usually is.
Conclusion
In this article, we’ve talked about what classification is, how it works, and how to measure the performance of classification systems. If we missed any important points that we should have included, please leave them in the comments below.